Can you imagine a world where computer vision algorithms not only grasp the big picture but also capture every intricate detail with pixel-perfect accuracy? Due to a new algorithm called FeatUp developed by MIT researchers and published on March 15 on ArXiv, this vision is now a reality. The FeatUp algorithm can capture both high and low-level resolutions at the same time. Its remarkable ability for preserving even the tiniest details while also extracting important high-level features from visual data is unmatched.
Traditional computer vision algorithms are good at understanding the big picture in images, but they struggle to keep all the small details, according to the researchers.
“The essence of all computer vision lies in these deep, intelligent features that emerge from the depths of deep learning architectures. The big challenge of modern algorithms is that they reduce large images to very small grids of ‘smart’ features, gaining intelligent insights but losing the finer details,” says Mark Hamilton, an MIT PhD student in electrical engineering and computer science, MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) affiliate, and a co-lead author on a paper about the project.
FeatUp has now changed this by helping algorithms to see both the big picture and the small details at the same time. It’s like upgrading a computer’s vision to have sharp eyesight, similar to how Lasik eye surgery improves human vision.
“FeatUp helps enable the best of both worlds: highly intelligent representations with the original image’s resolution. These high-resolution features significantly boost performance across a spectrum of computer vision tasks, from enhancing object detection and improving depth prediction to providing a deeper understanding of your network’s decision-making process through high-resolution analysis,” Hamilton says.
As AI models become more common, there’s a growing need to understand how they work and what they’re focusing on. Hamilton says, FeatUp works by tweaking images slightly and observing how algorithms react.
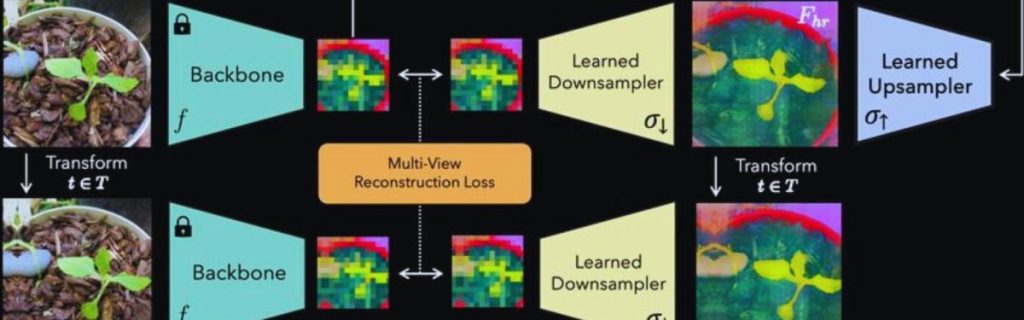
The FeatUp training architecture. FeatUp learns to upsample features through a consistency loss on low resolution “views” of a model’s features that arise from slight transformations of the input image. Description/Image Source: arXiv
“We imagine that some high-resolution features exist, and that when we wiggle them and blur them, they will match all of the original, lower-resolution features from the wiggled images.”
This process creates many slightly different deep-feature maps, which are then combined into a single clear and high-resolution set of features. According to Hamilton, the idea is to refine low-resolution features into high-resolution ones by essentially playing a matching game.
“Our goal is to learn how to refine the low-resolution features into high-resolution features using this ‘game’ that lets us know how well we are doing.”
This approach is similar to how algorithms build 3D models from multiple 2D images, ensuring the predicted 3D object matches all the 2D photos used. With FeatUp, the goal is to predict a high-resolution feature map that matches all the low-resolution feature maps created from variations of the original image.
The team also developed a special layer for deep neural networks to make this process more efficient. This improvement benefits many algorithms, like those used for identifying objects in images.
“Another application is something called small object retrieval, where our algorithm allows for precise localization of objects. For example, even in cluttered road scenes algorithms enriched with FeatUp can see tiny objects like traffic cones, reflectors, lights, and potholes where their low-resolution cousins fail. This demonstrates its capability to enhance coarse features into finely detailed signals,” says Stephanie Fu ’22, MNG ’23, a PhD student at the University of California at Berkeley and another co-lead author on the new FeatUp paper.
FeatUp isn’t just useful for understanding algorithms; it also helps with practical tasks like spotting small objects in cluttered scenes, such as on busy roads. This could be crucial for things like self-driving cars.
“This is especially critical for time-sensitive tasks, like pinpointing a traffic sign on a cluttered expressway in a driverless car. This can not only improve the accuracy of such tasks by turning broad guesses into exact localizations, but might also make these systems more reliable, interpretable, and trustworthy,” Hamilton explains.
Moreover, FeatUp’s flexibility is evident as it smoothly integrates with existing deep learning setups without requiring extensive retraining. This allows researchers and professionals to easily employ FeatUp to enhance the accuracy and effectiveness of various computer vision tasks, such as object detection and semantic segmentation.
For instance, if we use FeatUp before examining the predictions of a lung cancer detection algorithm using methods like class activation maps (CAM), we can get a much clearer (16-32 times) picture of where the tumor might be located according to the model.
The team hopes FeatUp will become a standard tool in deep learning in the days to come, allowing models to see more details without slowing down. Experts also praise FeatUp for its simplicity and effectiveness, saying it could make a big difference in image analysis tasks.
“FeatUp represents a wonderful advance towards making visual representations really useful, by producing them at full image resolutions,” says Cornell University computer science professor Noah Snavely, who was not involved in the research.
The research team has planned to share their work at a conference in May.
Brit strictly hates when someone says "the future". She considers herself a futurist and believes that there is no such thing as future yet.
Latest posts by Britney Foster (see all)
- AI-Powered PCs: Overhyped Trend or Emerging Reality? - August 21, 2024
- Princeton’s AI revolutionizes fusion reactor performance - August 7, 2024
- Large language models could revolutionize finance sector within two years - March 27, 2024



